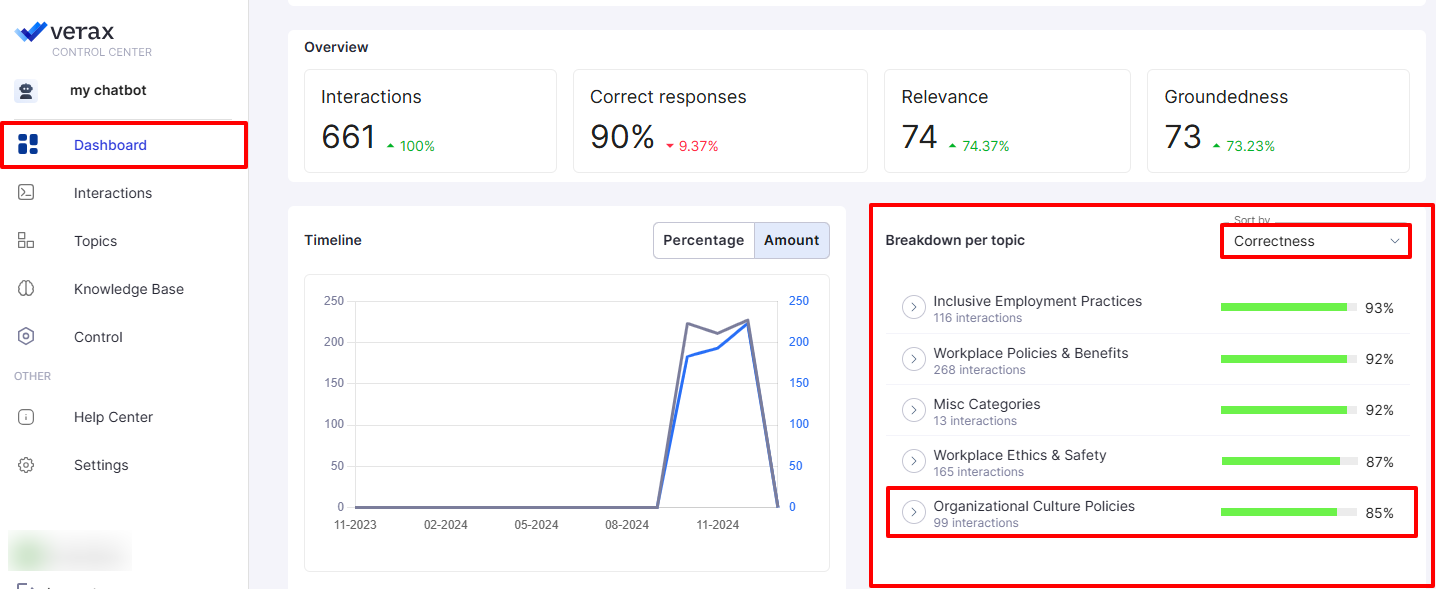
When Can It Happen?
1. Query Understanding Issues:
The system may not fully understand the nuances or specific demands of the query. If the query is ambiguous, complex, or uses domain-specific jargon, the retriever might fetch documents that are partially related but not fully aligned with the user’s intent
2. Ineffective Fusion of Retrieved Content:
Even if the retrieved documents are relevant, the generator might focus on the wrong details, leading to responses that are partially relevant but missing the core intent of the question.
3. Model Limitations:
If the generator itself lacks strong contextual awareness or reasoning ability, even well-retrieved documents may not lead to high-quality answers. For example, an older or weaker model may struggle to synthesize retrieved information effectively.
How to Fix It? 1. Improve Query Processing and Understanding
Enhance query reformulation: Rephrase user queries internally to reduce ambiguity before retrieval.
Use query expansion techniques: Add context-relevant terms to help retrieval focus on the right aspects.
2. Upgrade the Model
Replace the generator with a stronger model: If the existing model struggles with retrieval-based generation, consider switching to a more capable model.
Use a hybrid approach: If a single model struggles, try combining a retrieval-based model with a reasoning-focused model for better context handling.
3. Implement Feedback and Logging User feedback loop: Allow users to rate response quality and use this data to retrain retrieval and generation. Log failure cases: Track cases where retrieval seems correct but generation fails, helping diagnose model weaknesses. | When Can It Happen? 1. Inadequate Retrieval
Document Mismatch: If the retriever fails to fetch documents that are relevant to the query, the generator lacks the necessary context for a grounded response. This can happen due to poor retriever tuning or an incomplete knowledge base.
Retriever Limitations: Some retrievers may struggle with certain query types, especially those requiring nuanced understanding or highly specific knowledge.
2. Generator Over-reliance
Hallucination: Generative models, including those in RAG, may produce details that sound plausible but lack factual grounding in the retrieved content. This issue is more pronounced when models are trained for fluency and verbosity rather than strict factual adherence.
3. Ineffective Integration
Poor Fusion of Retriever and Generator: If the retrieval mechanism does not effectively rank or structure relevant documents, the generator may struggle to extract the right context from them. This can lead to responses that are only loosely connected to the retrieved data.
How to Fix It?
1. Improve Document Retrieval: Enhance the quality and scope of the document database.
Fine-tune or switch the retrieval method to better match the types of queries and data. 2. Tune the Generator:
Adjust generation parameters to reduce hallucination, such as lowering temperature or refining sampling strategies.
3. Enhance Integration Techniques:
Experiment with different ways to incorporate the retrieved information into the generation process, such as different attention mechanisms or integrating more explicit checks for data grounding.
4. Experiment with Hybrid Models:
Consider using a hybrid model that can better utilize both retrieved information and generative capabilities, possibly by integrating feedback from the generator back into the retriever for a second retrieval pass. 5. Post-processing and Validation: Implement post-processing checks to validate responses against the retrieved documents before sending them to users. | When Can It Happen? Weak Retrieval Constraints:
If the generative model is capable of producing highly fluent responses but lacks strict reliance on retrieved documents, it may generate plausible but ungrounded answers. This happens when the generator fills in gaps with learned patterns from pretraining rather than staying strictly within the provided retrieval context.
Retriever Is Not Powerful Enough: The mechanism that combines the retrieved documents with the generative process may not effectively ensure that the generated text relies on the input from the retriever. - The generator might lightly sample context from the retrieved documents or ignore less prominent details, leading to responses that are contextually relevant but not directly grounded.
Inaccurate Context Understanding: Sometimes, even if documents are retrieved, they might not be entirely relevant or specific enough to the query, prompting the generator to fill gaps with general knowledge that seems relevant but isn't based on the retrieved content.
How to Fix It?
1. Improve Document Retrieval: Refine the retriever's training: Ensure that the retriever is optimized to better capture query nuances and fetch the most relevant documents.
Expand and curate the knowledge base: Maintain a well-structured, high-quality information source that comprehensively covers expected topics.
2. Enhance Integration Between Components:
Strengthen retrieval-to-generation coupling: Ensure that the generator prioritizes retrieved content over general knowledge by refining how retrieved documents are incorporated. Adjust the model's training objectives: Incorporate objectives that penalize the model for generating content not supported by the retrieved documents.
3. Modify Generator Configuration:
Tune generation parameters: Adjust parameters such as temperature and top-k sampling to reduce the likelihood of speculative, ungrounded responses. Train with a focus on grounding: Where possible, train the model on datasets that emphasize grounding in provided texts to reinforce adherence to retrieval-based knowledge.
4. Utilize Post-Generation Validation: Implement a validation layer: Use automated NLP-based verification to check responses against retrieved documents, ensuring alignment and factual consistency.
5. Feedback Loop and Continuous Learning:
Incorporate user feedback: Track instances where the system generates relevant but ungrounded responses and use this data to refine retrieval and generation strategies over time.
|